Codeforces科学刷题指南,一图一表便够了
简要介绍如何科学地刷算法题,来提高自己解决问题的能力,并利用爬虫抓取Codeforces的题库,来分析题目难度以及算法分类的关系
无论做什么事,多尝试、找套路、然后刻意练习都是至关重要的。对信息科学竞赛(Olympiad in Informatics)爱好者来说,找套路的关键就是多刷题。然而题海茫茫,单以Codeforces来说,截止2017年1月3日,总共有3206道题。换言之,如果一个人足够勤奋,能够一天刷三道题,那也得快三年才能把题目刷完,而且题目数量还在扩充。所以盲目的刷题简直是浪费生命,本人从16年上半年一直按照题目解决人数从高到低排序,不断的刷水题。显然易见,刷水题的后果就是没有长进,熟悉的还是熟悉,不懂的还是不懂,唯一让自己开心的就是刷题数量的累积。所以科学刷题的本质在于不断挑战新高度,在一个平台练习足够久足够熟练之后,就要进入下一个难度平台。为了方便大家,我把Codeforces上截止2017年1月3日的所有题目的基本信息用爬虫收集了下来,并存储到excel里。更进一步,本文试图分析不同算法在不同难度等级上的出现频率分布,以及不同算法在不同难度等级上被解决次数的分布。最后,我会简要介绍的我的刷题观,以及如何爬取Codeforces上的信息。
先说结论
一张图
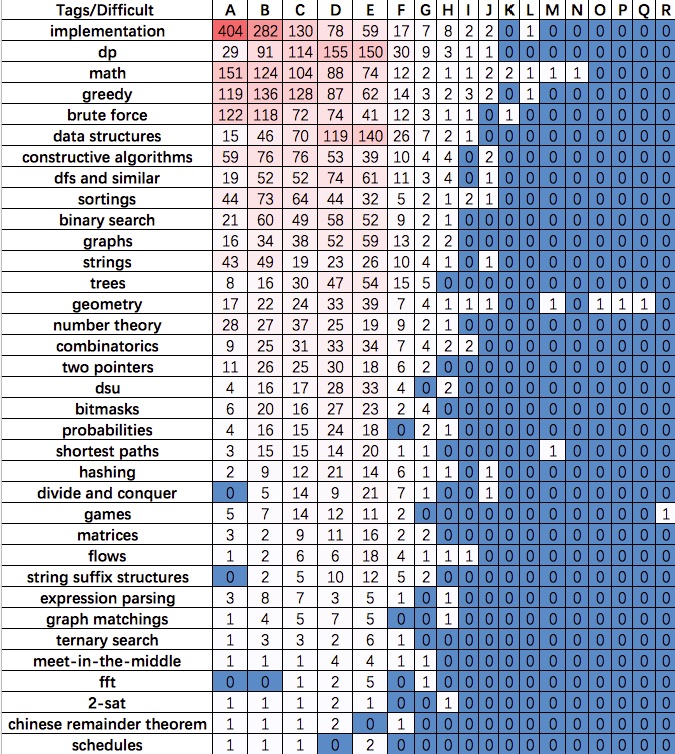
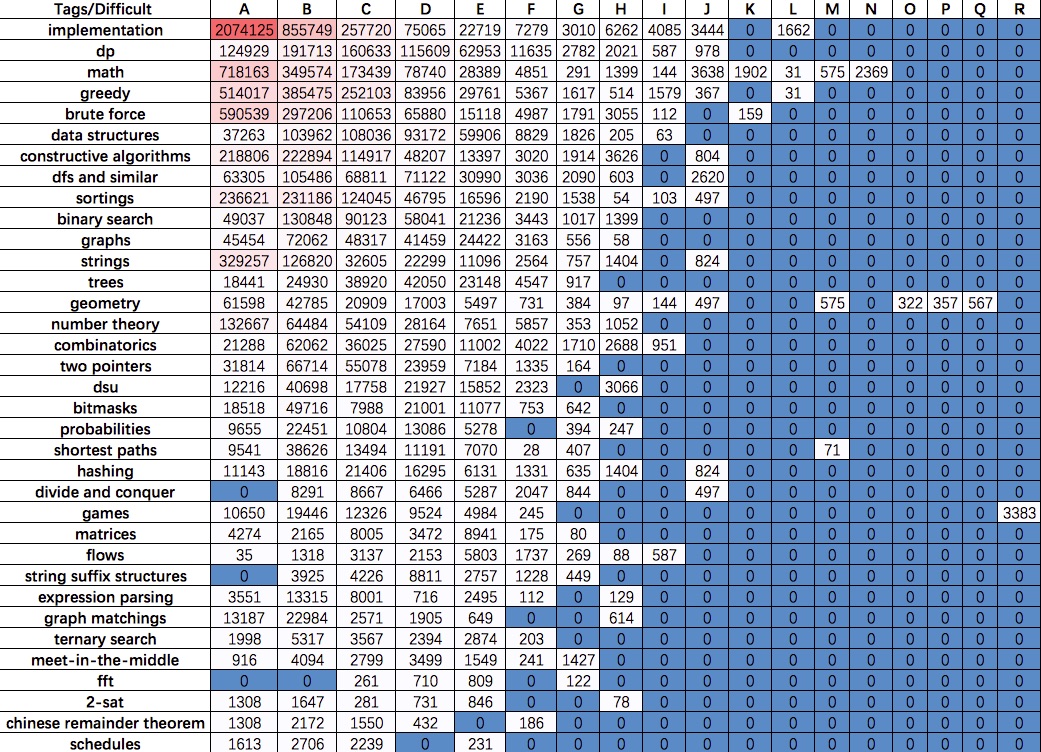
一张表
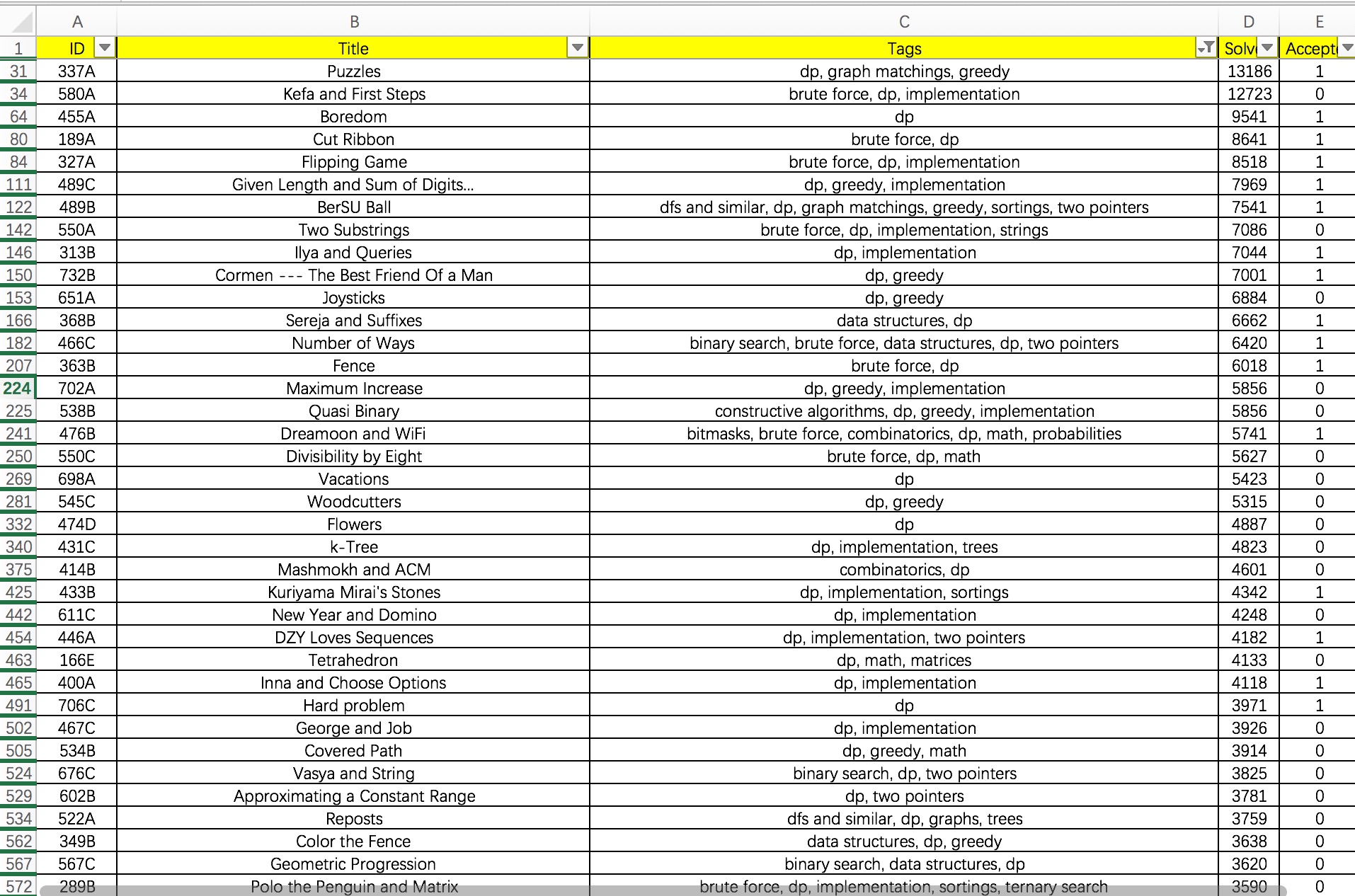
我的刷题观
这里搬来我在知乎上的回答,详见 LeetCode按照怎样的顺序来刷题比较好?
- 如果想提升自己的思维能力 ,可以按照AC率或者解决人数由低到高二分查找匹配自己当前水平难度的题目,然后适当挑战高难度题(二分时间复杂度是 \(O(\log N)\) ,至少比从易到难的 \(O(N)\) 节省时间)
- 如果想巩固某一专题 ,那自然应该按照tag来刷题,但是因为所用的方法在求解前已知,不太利于思维能力的提升
- 如果什么都不懂 ,那么建议随机刷题,一来可以涨见识,二来进步空间比较大
- 如果想提高AC率或者增加自信 ,那么建议刷水题
- 混搭以上策略 ,比如针对某一专题,然后用二分查找来选择问题求解
再有个建议,题目如果太难超过自己当前能力的话,尝试一定时间后还是老老实实看题解吧,人与人之间还是有天赋差别的,但区别在于经验可以慢慢积累。特别是即使做对题之后,还要想尽办法看有没有提高的余地,并参考别人的代码,看如何精简代码以及精简时间空间复杂度。

如何用爬虫获取信息
必要的库
1: import re |
爬取Codeforces的所有算法题
1: #%% retrieve the problem set |
标记已解决的算法题
1: #%% mark the accepted problems |
输出爬取信息到csv文本
1: #%% output the problem set to csv files |
分析题目难度以及算法分类的关系
1: #%% analyze the problem set |
下载本文源代码以及分析结果
本文源代码以及分析结果请见 我的Github ,或者点击链接下载: https://pan.baidu.com/s/1o7P8oT8 密码: 8dcb。
 本作品采用知识共享署名 2.5 中国大陆许可协议进行许可。欢迎转载,但请注明来自Mount Greenwicher的文章《Codeforces科学刷题指南,一图一表便够了》,并保持转载后文章内容的完整与无歧义。本人保留所有版权相关权利。
本作品采用知识共享署名 2.5 中国大陆许可协议进行许可。欢迎转载,但请注明来自Mount Greenwicher的文章《Codeforces科学刷题指南,一图一表便够了》,并保持转载后文章内容的完整与无歧义。本人保留所有版权相关权利。

微信打赏

支付宝打赏